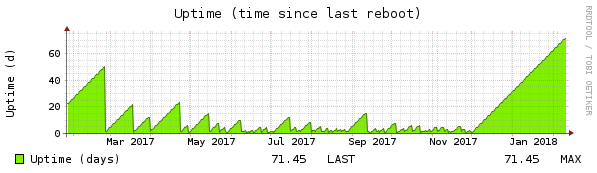
Well, well, well, after 71 days uptime the system can be considered stable:
Disabling the C6-sleep-state did it:
zenstates.py --c6-disable
Since last reboot the spectre/meltdown disaster happened. DKMS didn’t work any more, because archlinux updated gcc to 7.3 with retpoline support, so it blatantly refused to compile the nvidia module with a different compiler than the kernel was compiled with. That wasn’t really a problem, because X still restarted properly.
But there were other problems like systemd asking for passwords when it shouldn’t, dbus out of date and so on. Well, that’s what you get when running a rolling distribution. So I thought it was time to schedule a kernel re-compile and a reboot.
The re-compile was harder than expected. To put it short:
- When following the official documentation, do the checkout in an empty directory
- edit prepare() to do make oldconfig and make menuconfig in this order
- Don’t forget to uncomment and change pkgbase to linux-ryzen!
- Don’t makpkg -s on an encrypted volume 🙂
- If DKMS complains about a compiler mismatch on pacman -U, do IGNORE_CC_MISMATCH=1 pacman -U …
After a successful reboot I decided to install the fallow 16 GB of ram I initially purchased, since RAM timings weren’t really the problem. Now I have a workstation with whopping 32GB RAM:
# free -m total used free... Mem: 32167 5521 8478... Swap: 16382 0 16382
I kept the RCU_* setting, so let’s see how it turns out. Keeping fingers crossed!


