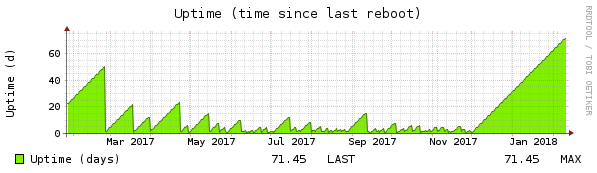
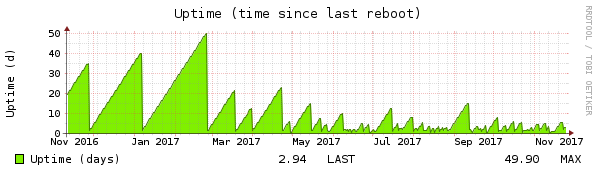
Take 3
Of course neither the new memory nor the BIOS update fixed the random crashes, but fortunately I’ve got another hint: Maybe it’s a linux-specific problem, and not one with memory timing. This post suggests that it’s a problem with C-States and RCU. Adding the following kernel command line parameters should help:
processor.max_cstate=1
rcu_nocbs=0-11
As always, nothing is as simple as it seems 🙁
The C-States
For max_cstate to take effect, I had to actually enable Global C-State-Control in the UEFI-thingy of my mobo! The default was Auto, which in turn defaulted to Disabled. After enabling it, dmesg reported this:
ACPI: ACPI: processor limited to max C-state 1
Before that, there was no mentioning of C-states in the kernel log, so I doubt that it has any impact, but one should never give up hope!
The RCU-Thingy
What it is (quoting Paul E. McKenney from LKML):
Read-copy update (RCU) is a synchronization mechanism that was added to the Linux kernel in October of 2002. RCU achieves scalability improvements by allowing reads to occur concurrently with updates.
It’s much more likely to be the cause of the problem since I once saw something like this after a reboot on the console:
The process was “systemd” instead of “DOM Worker”, but that shouldn’t matter. Anyway, the parameter rcu_nocbs=0-11 has no effect if the kernel config option CONFIG_RCU_NOCB_CPU is not set. Guess what, in the stock archlinux kernel it’s unset, lucky me!
So I ventured out to compile a custom kernel for arch. That turned out to be disappointingly easy! The available documentation just works ™! Four hints, though:
- Uncomment “make menuconfig”
- Edit /etc/makepkg.conf and set MAKEFLAGS to “-j<no-processors+1>” to get parallel builds
- If you have a nvidia graphics card and use the proprietary driver, keep in mind that you have to rebuild that one, too. Once again, that was ridiculously easy. Just install nvidia-dkms before updating the kernel with pacman -U and it will be built automagically when you install the new kernel! Detailed instructions are here.
- Don’t forget to update your grub-config with grub-mkconfig before rebooting!
Offload RCU callbacks from CPUs: 0-11.
should be in dmesg after a reboot, otherwise it didn’t work. I’m waiting with baited breath how it turns out!
Previous parts of my adventure: Part 1, Part 2.